
有一些专门针对网站克隆爬取的软件,如 WebZip、awwwb.com 等等,据说挺好用的。这里我给大家介绍一款程序员最爱的网站克隆爬取工具 – HTTrack,而且是开源的。
什么是 HTTrack?
WinHTTrack HTTrack 是一款简单易用的离线浏览器实用工具。该软件允许你从互联网上传输一个网站到一个本地目录当中,从服务器创建递归所有结构,获得 html,图像以及其它文件到你的计算机当中。
相关的链接被重新创建,因此你可以自由地浏览本地的网站(适用于任何浏览器)。
你可以把若干个网站镜像到一起,以便你可以从一个网站跳转到另一个网站上。
你还可以更新现存的镜像站点,或者继续一个被中断的传输。
该带有许多选项和功能的装置是完全可配置的。
该软件的资源是免费开放的!
HTTrack 的安装和使用
HTTrack 支持 Windows、Linux 和 MacOS 等主流的操作系统,且针对 Windows 而言,HTTrack 有可视化界面的支持,效果如下:
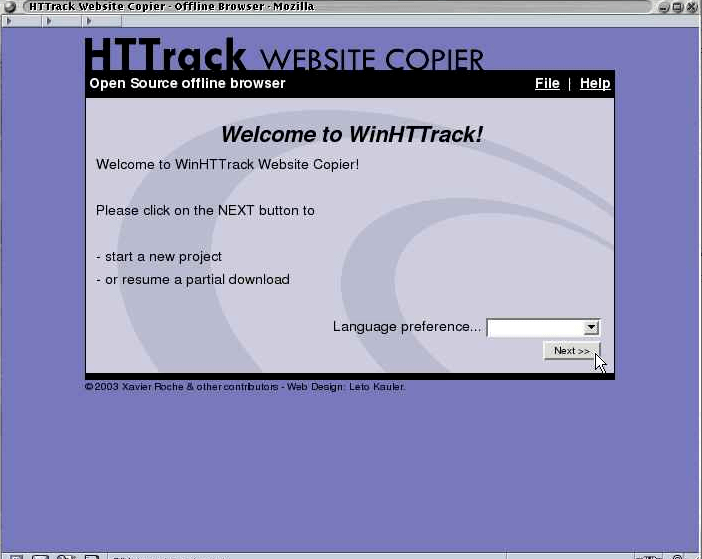
Windows 下安装:
通过 http://www.httrack.com/page/2/en/index.html,Download 下载对应的版本即可。
查看结果

把之中的,localhost.com 文件夹就是你爬取下的网站。

但是发现打开后,有一个报错,提示 cdn 的 js,无法直接访问。
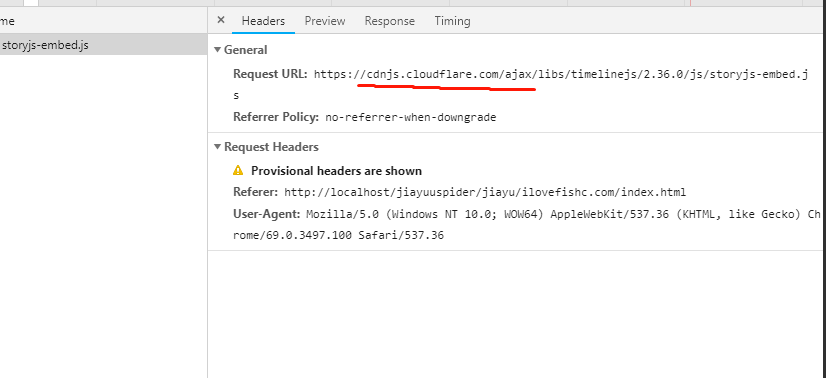
那这种,我们只能去 cdn 上给下载到本地了。
下载后发现是有路径错误,我们打开代码发现全是加密了。
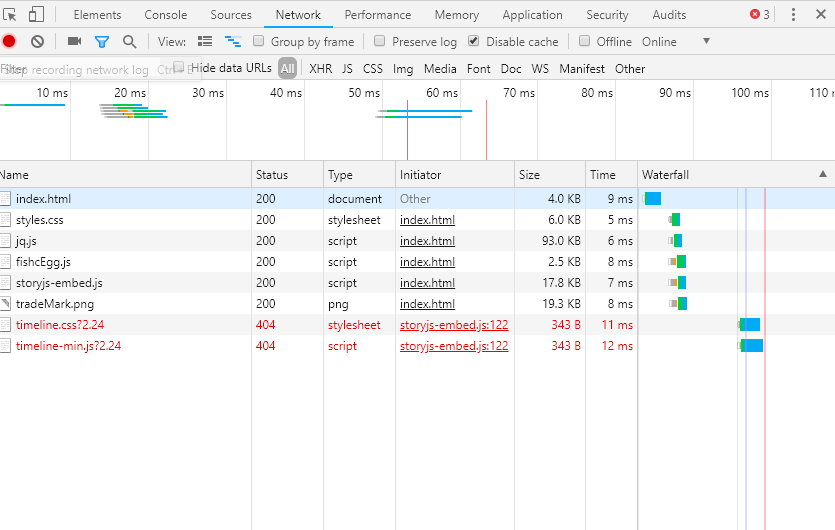
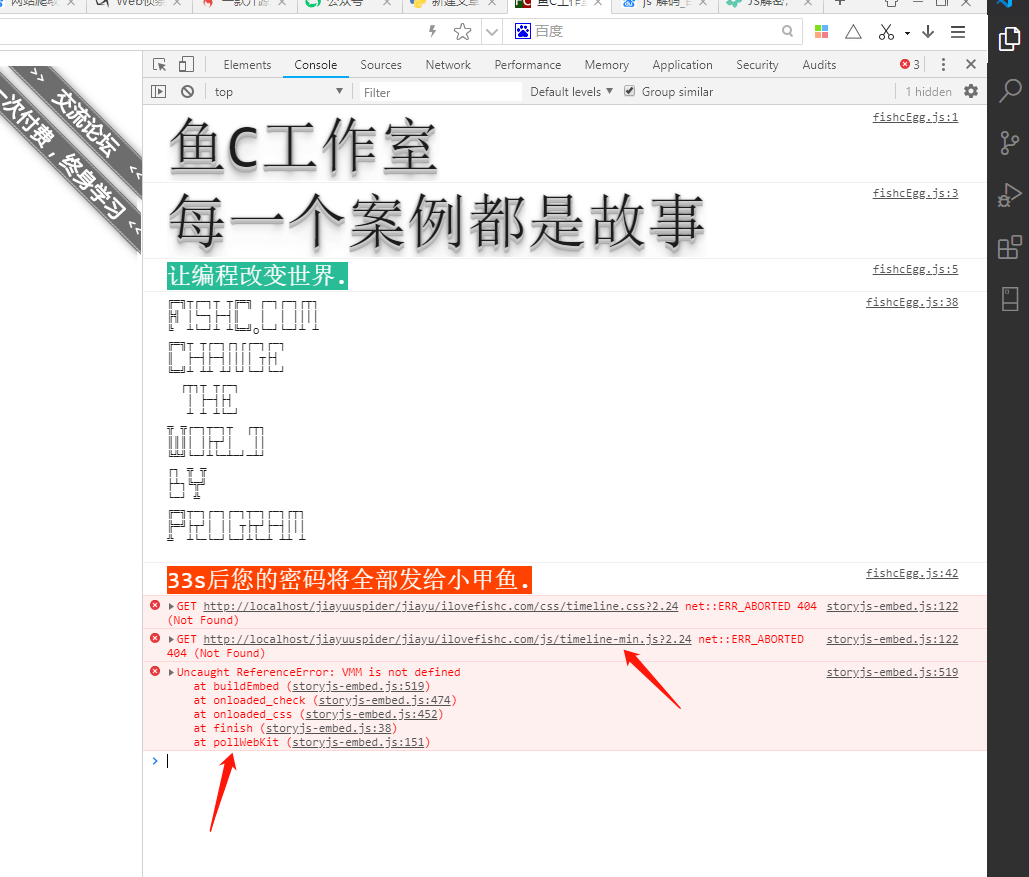
打开报错地方的 js 代码:
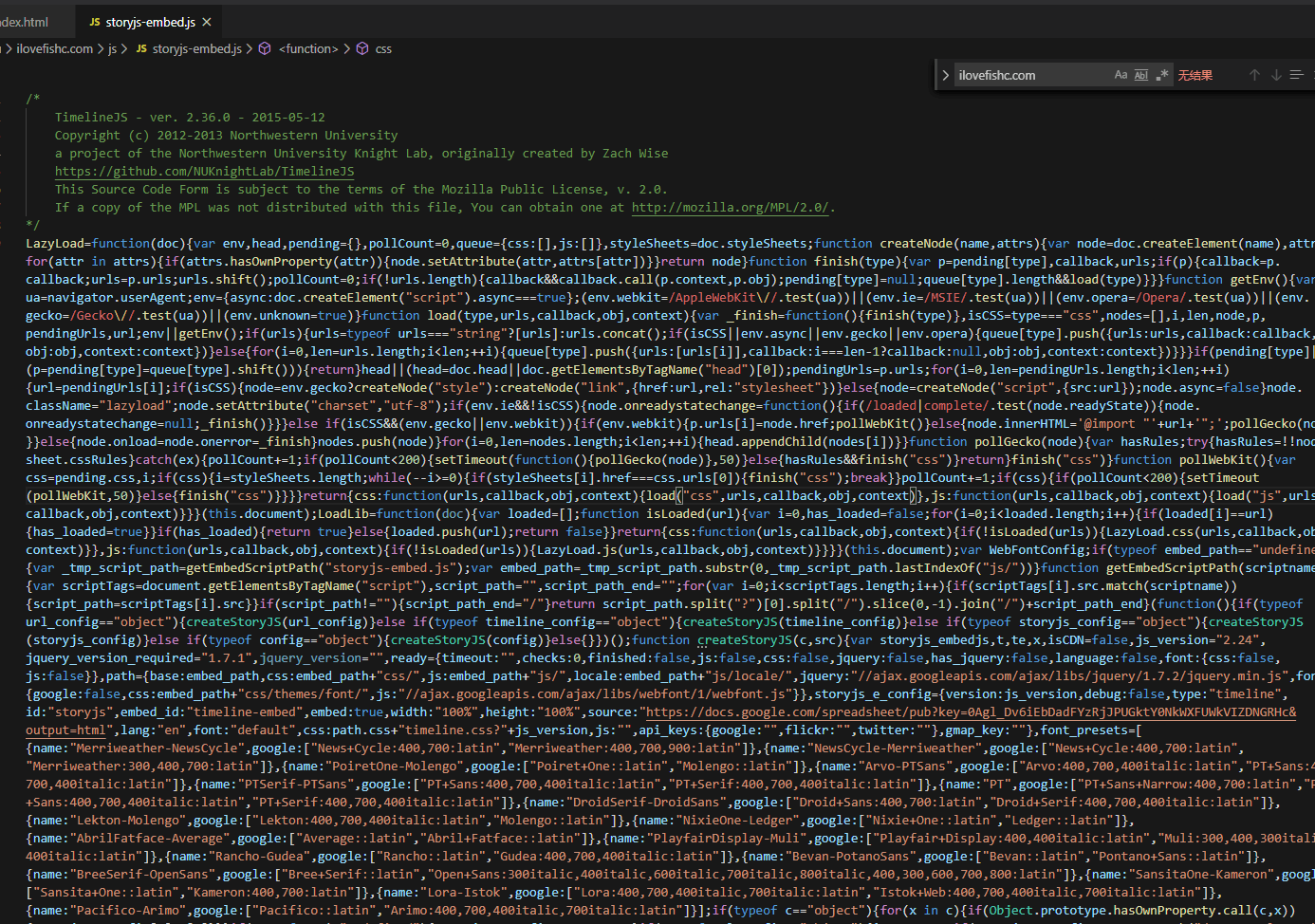
好吧加密了,我们解一下。可以直接使用 js 解密工具。
解密后 好看多了。
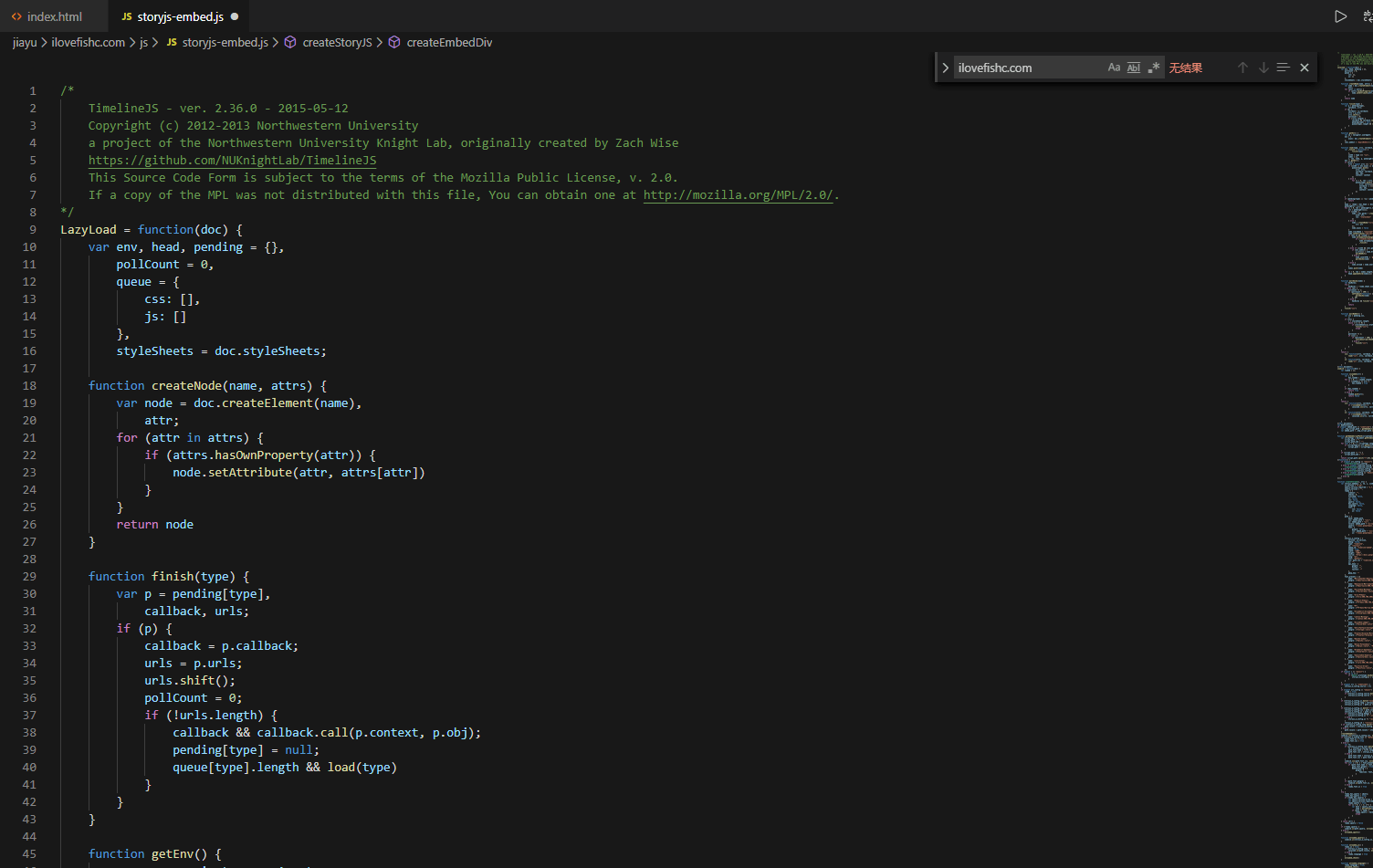
经过一番代码解析,寻找。具体就不提了。
我们把路径改正确。
改正确后,我们发现,缺少一个 data.json。文件
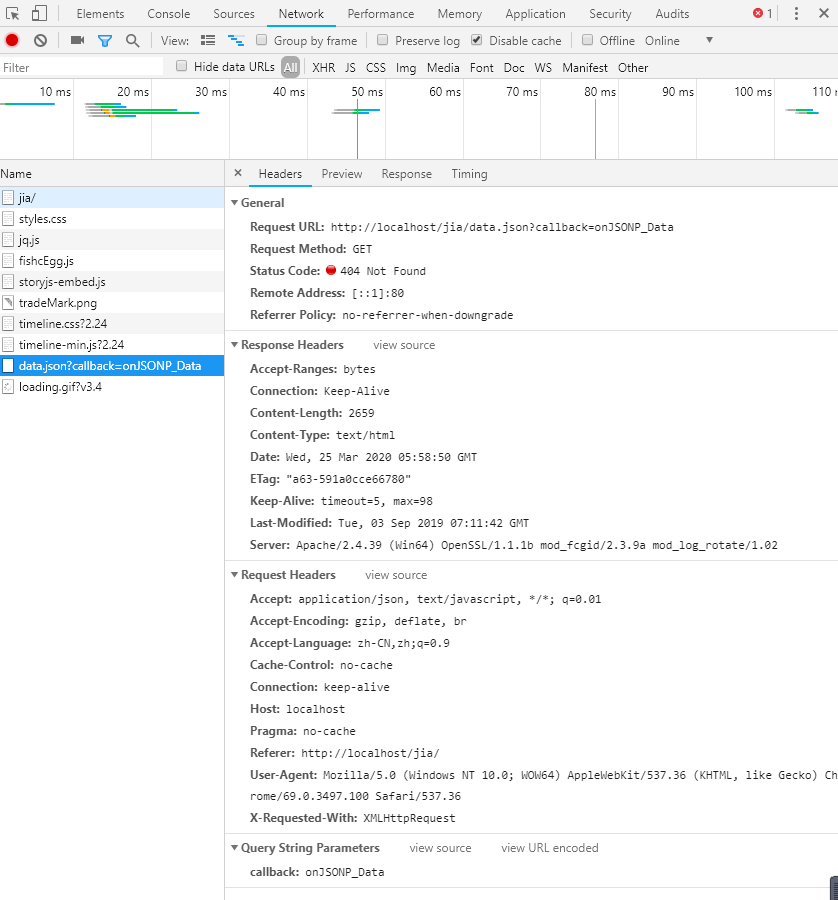
这是因为原网站,引用了一个时间轴插件,这个插件挺好的,献上下载地址。https://www.php.cn/xiazai/js/4818
那我们只能去原网站把 data.json 下载下来了。
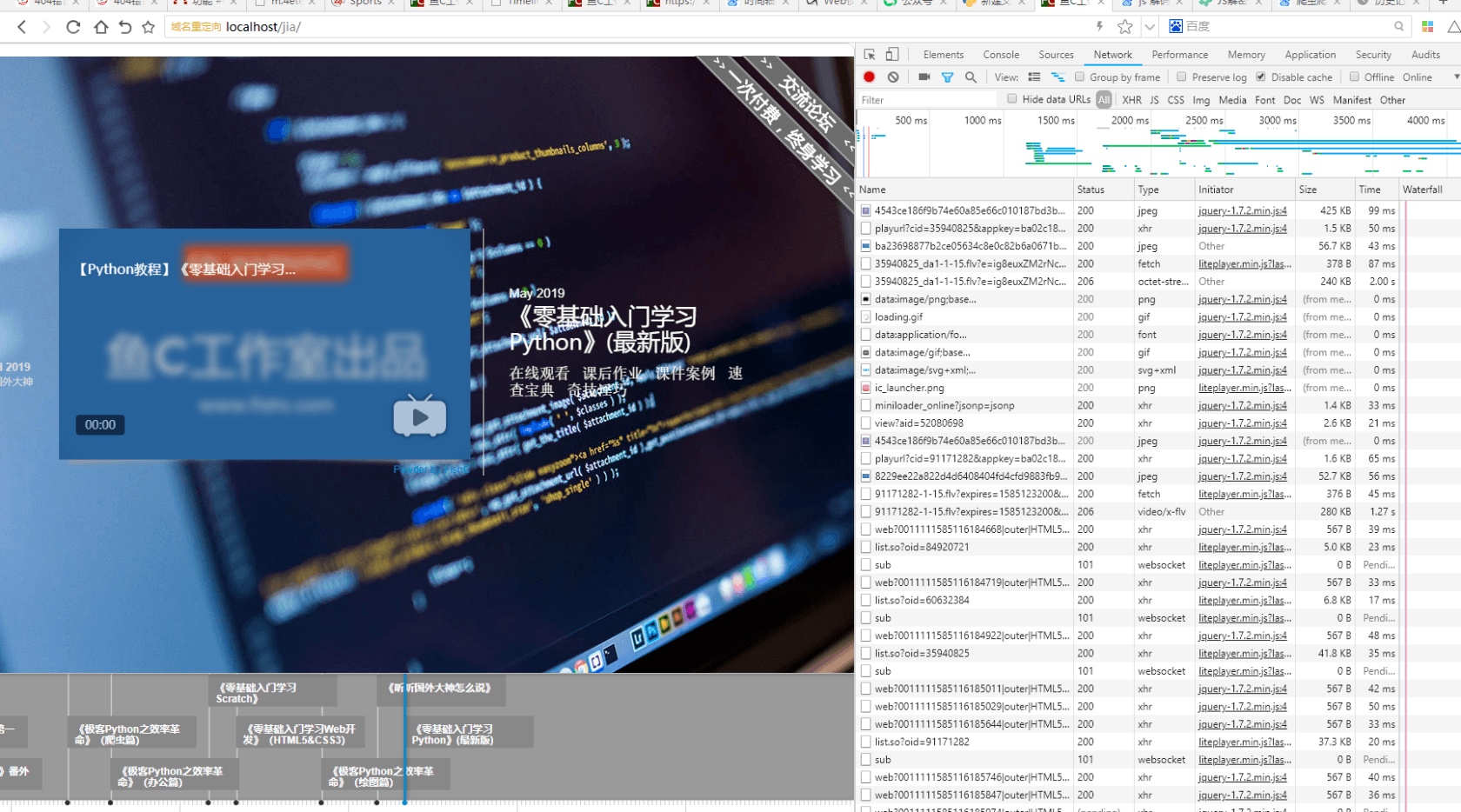
引入后,打开网站。
成功
答疑,有些小伙伴想,为什么不直接 ctrl+s 呢?而是要配合 httrack?
我放目录图你就知道了。
httrack 的目录:
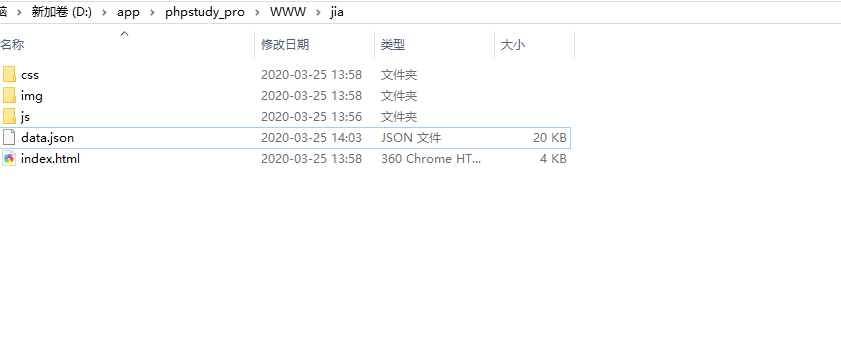
ctrl+s 的目录:
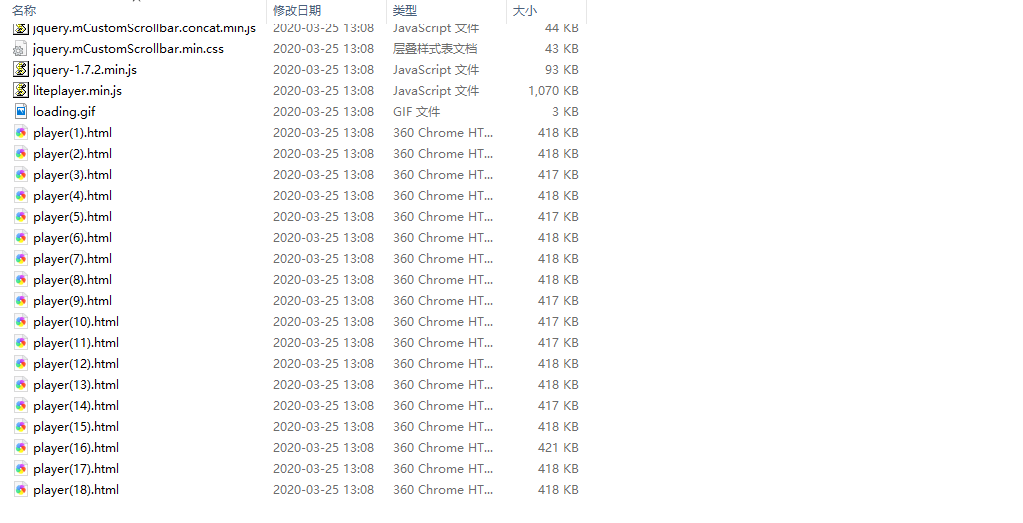
好啦,今天就到这里。如果喜欢研究爬虫,那就给我点赞,我会出一个 python 爬虫小课!
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章


暂无评论...